

A Simple Guide To KDD Process in Data Mining

Overview: Knowledge Discovery in Databases (KDD) refers to transforming raw data into actionable insights or intelligence. It can be used interchangeably with data mining, but KDD covers a broad range with the use of agentic AI, data science procedures, and human oversight to predict models hidden in the data.
Why KDD is the Backbone of Modern Business Intelligence
Data is mounting exponentially through IoT sensors, images, social media, videos, and multimodal AI. We need to seriously understand what it states. But raw data is “noise” until it passes via the KDD pipelines. It actually makes decision-making easier.
A series of data science procedures are used to filter relational patterns, which solve specific business problems. This AI-driven era is not just about peeping into the past but also about leveraging real-time analytics, which makes the voice of data clearer. So, predicting trends before their elevation is possible with the KDD procedure. This method can be used to determine fraud patterns, risks, cybersecurity flaws, and customer behavior. Once discovered, making critical decisions seems like a walkover.
How Does the Knowledge Discovery Process (KDD) Work?
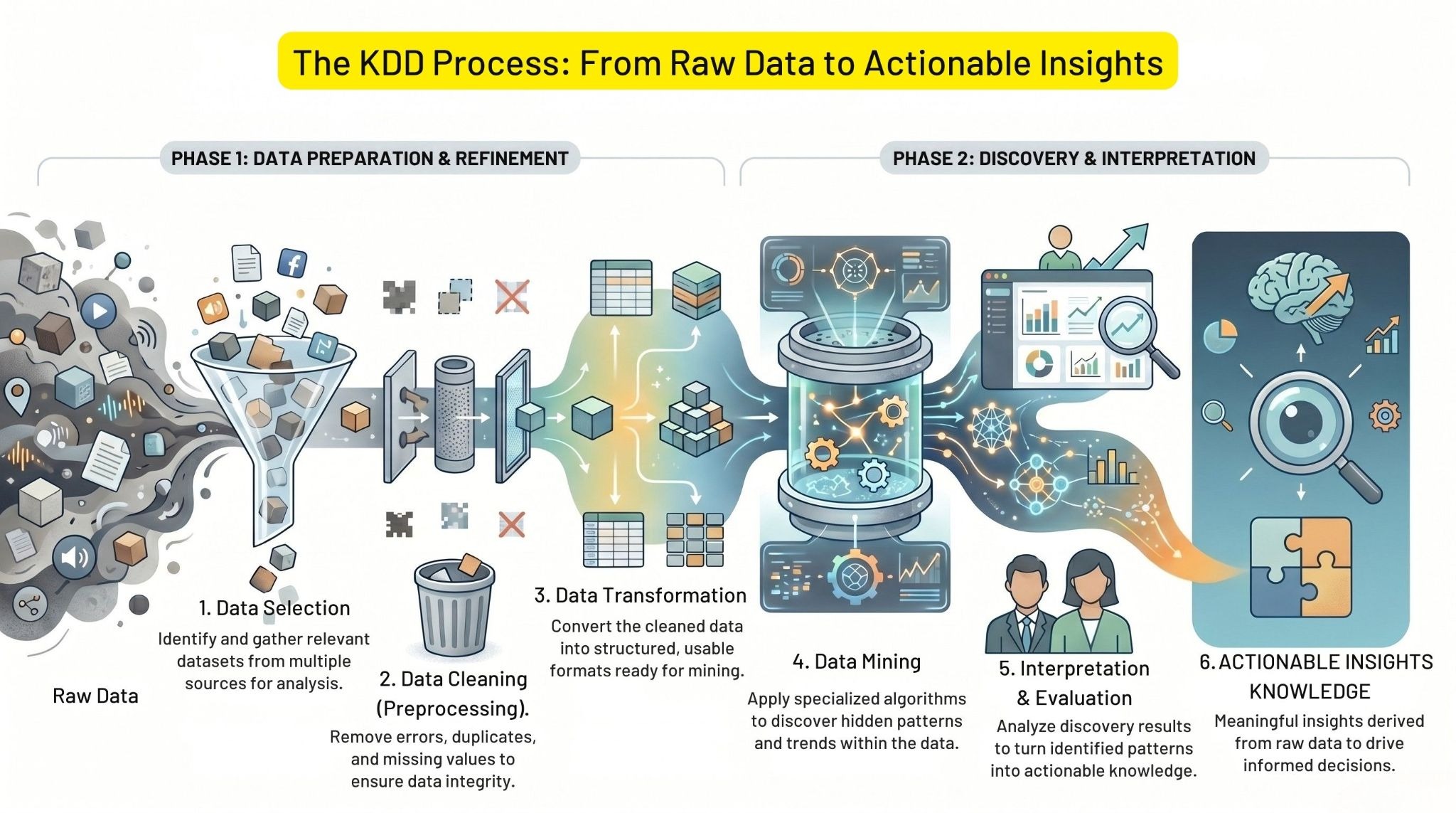
This process requires some manual and digital resources. For brainstorming, data scientists, skilled BI & analysis experts, and researchers are required. The tools and methods would depend on the size, type, and ultimate expectations from this knowledge mining process. Later on, the driven results may become machine learning and artificial intelligence. It completely depends on the purpose of why data mining is required.
Steps of Knowledge Discovery Database Process
Let’s get through the steps of the Knowledge Discovery Process (KDD).
Step 1: Intelligent Data Collection
This step involves a team of researchers and collectors, which helps in extracting data from diverse environments such as data lakes or cloud warehouses. The data requires restructuring and cleansing there. In this case, many experienced data mining companies like Eminenture prioritize “clean-at-source” guidelines to remove noises during data migration.
Step 2: Preparing & Profiling Datasets
The pre-processing prepares data to be transformed into consistent profiles after data collection. Some experienced data mining companies like Eminenture emphasize removing oddities early so later its transformation becomes seamless.
Step 3: Neural Data Cleansing
This involves removing "noise"—corrupt, incomplete, or duplicate files. It is done through cleansing, which is about removing noises and redundancies from gathered data. For neat and clean databases, the following subsets are followed:
- De-duplication
- Normalization
- Standardization
Step 4: Seamless Data Integration (ETL)
This process requires combining data from multiple sources. This process involves extraction, transformation, and loading (ETL) to synchronize data from multiple sources to be placed into a unified environment for deep analysis.
Step 5: Advanced Data Analysis
Getting deep into insights is analysis, which needs some fresh, niche-based, and relevant datasets in a standardized format so they can be filtered through advanced algorithmic filters.
- Neural networks to discover complex patterns from data.
- Decision trees & regression help in foreseeing business results.
- Clustering is typically preferred to segment customer behaviors.
Step 6: Data Transformation & OCR
This step typically ensures the conversion of mixed forms of data, like PDFs or handwritten notes, into identical digital formats using OCR and automated auditing. All data must be machine-readable so it can be automatically streamlined for mining. In some cases, scripting in Python or any other language can be used.
Step 7: Predictive Modeling & Mining
As it’s the most crucial stage, using scripting ensures fast extraction of patterns that should complement specific business objectives. Thereafter, these models are verified to ensure accuracy.
Step 8: Validating Models (Evaluation)
This step involves a data scientist who evaluates the intent score of each model. This professional validates models and even visualizes data to discover if they actually fit the predictive goals by using processes like classification and characterization.
Step 9: Knowledge Presentation & Visualization
Insights cannot help if they are not comprehensive. Some experienced data mining companies use tools like Google Looker Studio to convert into visual reports. Moreover, they set discriminant rules that leaders can act upon instantly.
Step 10: Execution & AI Automation
Finally, the derived decisions or results are applied to various applications or machine learning. Once done accurately, KDD results feed machine learning models for artificial intelligence or AI. This is how autonomous AI agents are born to execute business plans with minimal human intervention.
Conclusion
KDD or knowledge discovery for databases, is a crucial process that sets the background for AI development. Many agentic AIs are the result of this process. It is the process of converting raw or crude details into insightful details that can be helpful in transforming results into artificial intelligence. Many certified data mining companies & experts use it for multiple purposes. This process involves multiple steps, ranging from intelligent data collection to AI automation for the agentic AI revolution.
.jpg)


.jpg)

Post Comment
Your email address will not be published. Required fields are marked *